This is the second post in a series, documenting the progression of the project and the challenges I faced at each stage. I’m intending these posts to be almost reflective in nature, rather than very technical, though I will lightly justify some technical choices also. Once I feel that I can move the project out of a prototype stage, I’ll put up a more formal page documenting the technology and some overall reflections.
Following on from part one, I have a Python script to scrape UQ’s course and program websites and now need to design and build a database to store the scraped data.
ER Diagrams and Database planning
I used Draw.io to do the initial diagramming, in both Chen notation as I was taught at university, and in Martin notation as is used more commonly used in the industry. Many of us used Draw.io during our university studies for its collaborative functionality as part of the team-based database design project. We could discuss the diagram and easily move objects around in real-time, either completely remotely or just on separate computers sitting next to each other. I kept using Draw.io for my own project since I was already experienced in it; and also using Google Drive, it was automatically saved and versioned as well as being accessible from any Internet-connected PC.
I like that Chen notation shows the relationship between entities and we don’t need to include the tables created during the mapping steps.
Design Rationale and Mapping
I needed to store information about the following entities:
- Course
- Plan/Program
- School
- Faculty
A Course entity contains attributes such as CourseCode (the Primary Key), Title, Coordinator; and the important multi-valued attributes Semesters and Prerequisites. Semesters and Prerequisites would be mapped to new tables. Prequeresites ends up being a correlation table just mapping CourseCodes to other CourseCodes.
I figured that a Course is related to a Plan/Program since Courses make up Programs (of study). A Course is offered by a School. Schools have a title and a Faculty (entity) that manages that School. A Faculty also offers a Plan so it needs to be an entire entity by itself so both relationships are available.
My original Chen Notation diagram was complex and had many relations and relationships:

Unfortunately, I’ve lost some detail when I decided to simplify it during the mapping stage. After diagraming it using Martin Notation it seemed quite hard to comprehend.

Originally, I wanted to be able to correlate faculties against schools and programs; and schools and faculties against individual courses. This way, as well as having a database to help choose subjects, I could also run interesting statistical analysis against the relationship between courses/schools/faculties/programs to determine things like… what faculty has the most programs, or what school has the most individual courses.
My colleague suggested (separately of my unplanned redesigns) I use the ER diagramming tool built into MySQL Workbench. It uses Martin notation and has the nice feature of being able to generate an SQL script based on the diagram.
MySQL Workbench
Following on from my Martin Notation on Draw.io, following is one of my early ER diagrams I made in SQL Workbench:

After discussions with my friend, I further simplified the ER diagram and model:
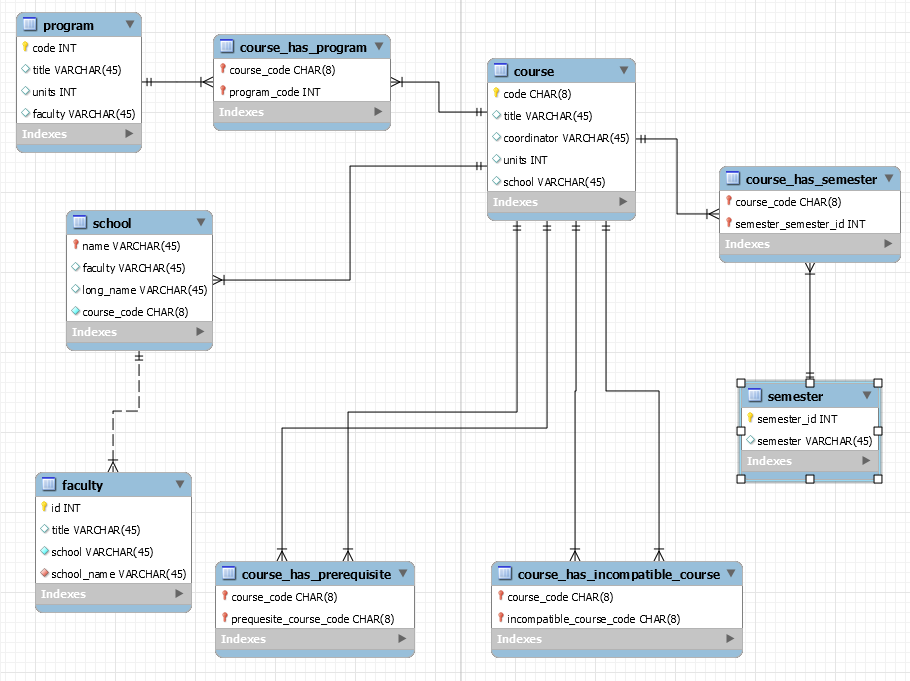
Clearly, the model and diagram are now much simpler and easier to understand, with the Course table still taking centre-stage. But still, Program is no longer linked to Faculty. (Having said that, an equijoin with a nested query would likely work and still keep the database simple.)
Recently I have removed the Faculty table since it didn’t really need to exist, and I figured I should just store them in columns against each School instance (row) given that each school only has one faculty.
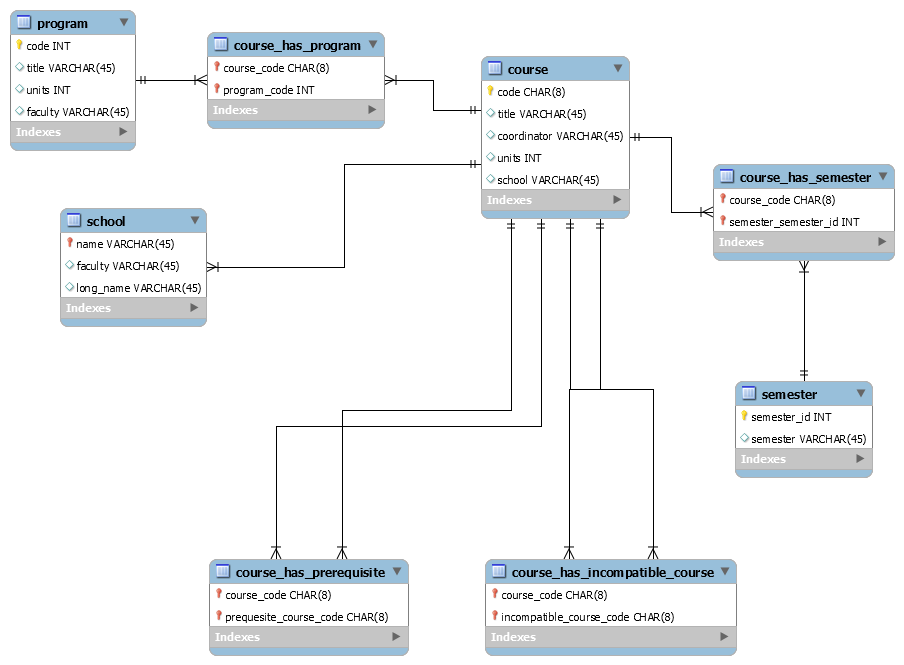
Final Thoughts
Of course, while it’s now very easy to insert the course data into the database, I have also lost all the faculty-school-program relationships by removing that table. Now, more sub-queries would be required to cross-reference it. I decided that since there would only be 20-30 Schools across five Faculties, the time saved in the queries didn’t warrant the extra complexity. There are only about 3000 courses in total and probably a few hundred programs so I didn’t think speed was really an issue.
Also, I really wanted to get the database created so I could at least prototype the Python database saving code.
Now I actually have the Python script saving things to the database, I’ll probably go back and either change the database again or scrape the data first then go and reprocess the database to rebuild the Faculty table once the entire dataset is scrapped. Having the experience of redesigning the database a few times I feel I am in a better place to go back and create a database structure similar to what I wanted originally.
Building the database itself presented further technical challenges as I was also on holidays at the time….