One small project I’ve been working on is a small desktop app written in C#.net to remove Unicode characters from text strings. I had a legitimate need for this as often databases or older applications will only support plain ASCII text. I had originally thought to write it in Python, but I figured that a native desktop application would be simpler to use. Following, I will discuss the intended workflow for the application with some technical discussions after that.
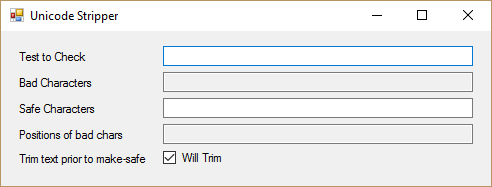
- Paste the text you suspect has some Unicode characters into the first box.
- Generally speaking, you will want to trim white space before processing, but in case there is a specific reason not to, I’ve left that as an option.
- Any non-ASCII characters found will be displayed in the second box and, conveniently, approximately at the same position as the original string.
- As a further aid, the fourth box shows the position in the original string of the suspect characters.
- The now safe string (as non-ASCII characters have been removed) is displayed in the third box. From here you can either copy the text as is or use the second and fourth boxes as a guide to manually update the safe text in the third box. For instance, the unsafe character might be an “–” (n-dash) and you might be happy just to type a standard “-” (hyphen) in approximately that same position.
Technical Discussion
The process is actually quite simple – helped along by the code running every time the text box changes which guarantees completeness: Every time the text is updated, the code reads each character and checks its character code. If it’s “63” which is a “?” (question mark), we compare by strings that the character is not actually a question mark. (This is because the characters that don’t fit into the ASCII table are converted (by .Net) to a “?” anyway.) If it’s a question mark anyway, we leave it alone. If not we do a few things at once:
- Grab the original character in question and display it in the second box with calculated padding.
- Update the list of positions within the original string with the locations of the unsafe characters.
- Make another string without that character. And output it.
Because this entire code basically re-runs upon edit, we only need to loop over the entire string to do the initial checking (and not copying to a new string), then when the whole string is traversed, display the characters and their positions as appropriate. By inverting the whole operation, the logic and code is much simpler than actually removing some text from other text.